
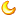
爬虫非法多字节问题
bs4_text.pyfrom bs4 import BeautifulSoup
file=open("text.txt",'r')
context=file.read()
soup=BeautifulSoup(context,"html.parser")
links=soup.find_all("a")
for link in links:
print(link.name,link["href"],link.get_text())
file.close()
text.txt
<html>
<head>
<meta http-equiv=Content-Type content="text/html;charset=utf-8">
</head>
<body>
<h1>标题1</h1>
<h2>标题2</h2>
<h3>标题3</h3>
<h4>标题4</h4>
<div id="content" class="default">
<p>段落</p>
<a,href="https://www.baidu.com">百度</a>
<ima scr="https://www.,png"/>
</div>
</body>
</html>
结果
Traceback (most recent call last):
File "C:\Users\86177\Desktop\didi\编程\爬虫\bs4_text.py", line 3, in <module>
context=file.read()
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa2 in position 109: illegal multibyte sequence
[Finished in 437ms]
